
docker-compoesでpython(scrapy / splash)のスクレイピング環境構築
スクレイピングをするために、scrapy + splash を利用した際、環境設定はdocker-composeで行いました。
その際に発生したエラーメモです。
事象2が解決できず、いったんペンディング中。。。スクレイピング部分はselemiumに戻す方向で検討中。
だれかコメントいただけると幸いです。
ソースは以下に格納しています。
事象:1 DNS lookup failed: no results for hostname lookup: splash
twisted.internet.error.DNSLookupError: DNS lookup failed: no results for hostname lookup: splash.
原因:
setting.pyのSPLASH_URL = ‘http://localhost:8050’が設定されていなかった。
詳細には、setting.pyを修正した後に、docker-compose up -dで実行したためリビルドされず、
setting.pyが入れ替わっていなかった。
そのため、docker-compose up -d –buildで実行しなおしたらエラーが解消した。
事象:2 Connection was refused by other side: 111: Connection refused.
File "/usr/local/lib/python3.6/site-packages/scrapy/core/downloader/middleware.py", line 43, in process_request
defer.returnValue((yield download_func(request=request,spider=spider)))
twisted.internet.error.ConnectionRefusedError: Connection was refused by other side: 111: Connection refused.調査1:splashが起動しているか確認
setting.pyで指定したSPLASH_URL = ‘http://localhost:8050’にブラウザからアクセス
以下の画面が立ち上がることを確認。
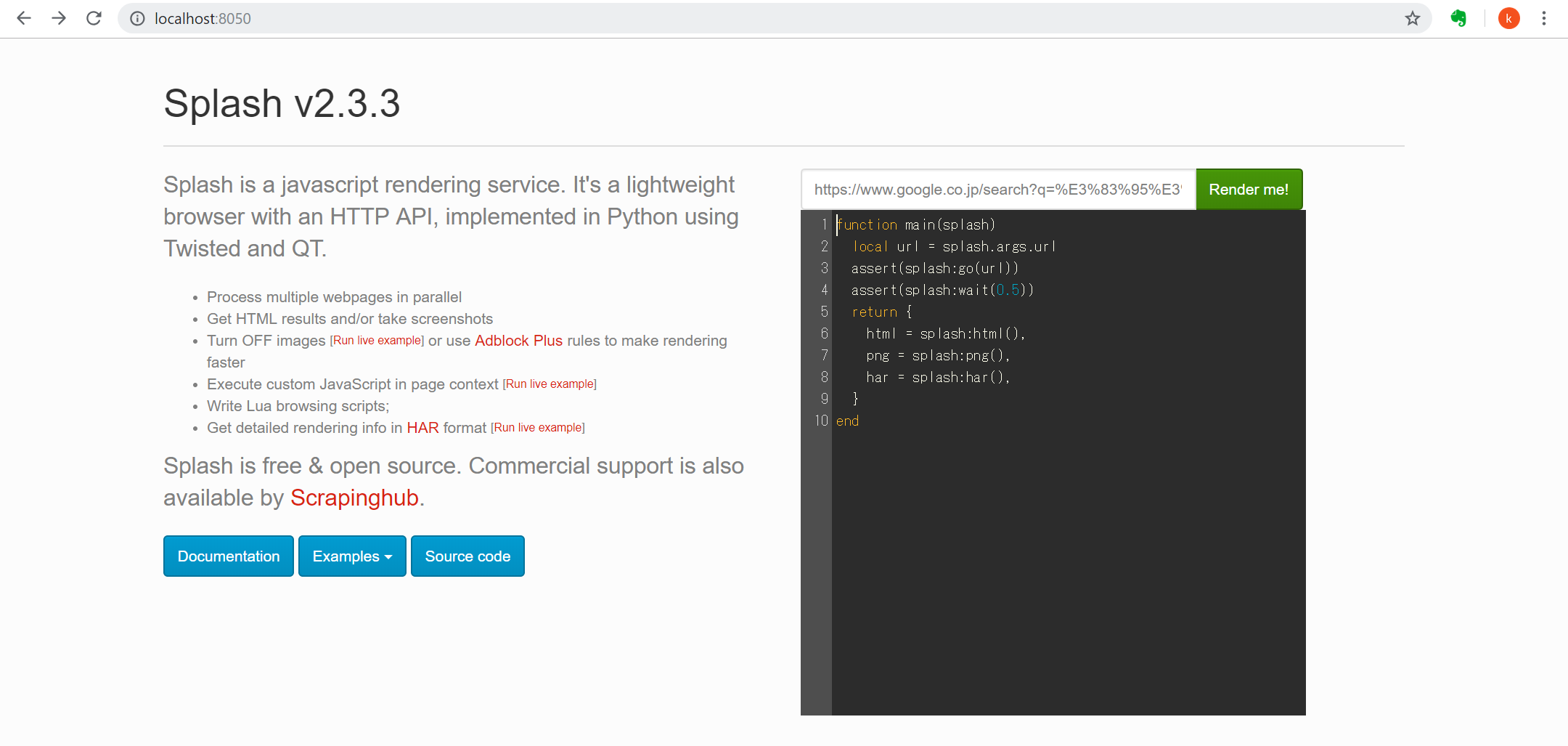
ちなみに、検索したいURLを張り付けて、検索を実行してみて動くことを確認
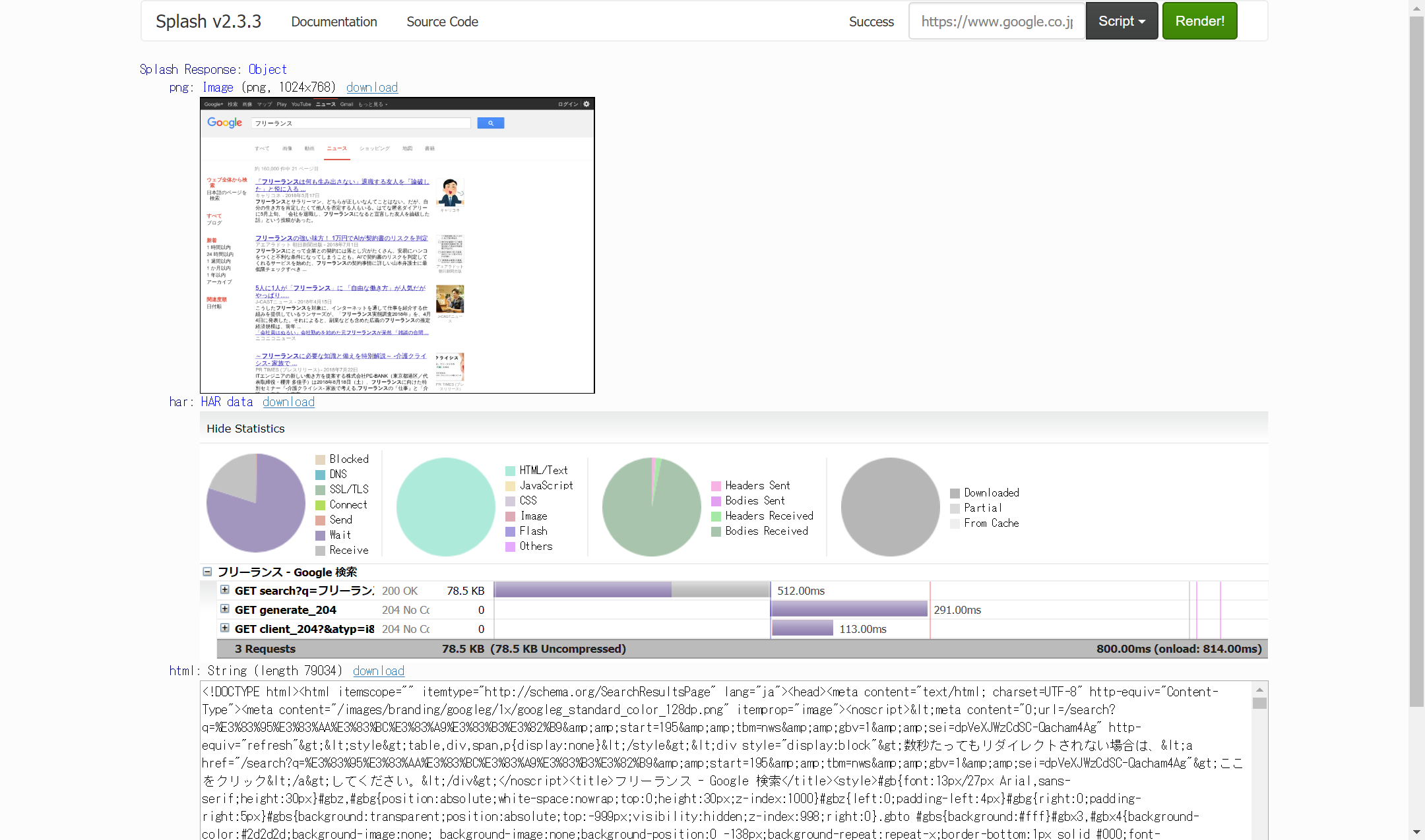
調査2:コマンドプロンプトからcurlを実行して確認
以下の本家サイトからZIPを取得して、「C:\Program Files」へコピペ。(%PATH%に通っていればどこでもOK)
https://curl.haxx.se/download.html

実行結果で、HTMLの内容が表示されれば問題なし。
C:\Users\kenta>curl http://localhost:8050/render.html?url=http://www.google.com/"
<!DOCTYPE html><html itemscope="" itemtype="http://schema.org/WebPage" lang="ja">
<head><meta content=">name="description">
<meta content="noodp" name="robots">
<meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title><script nonce="sUq6fqwxKAppxMt5MeRF9w==">
~省略~原因:調査を一時中断してます。。。
原因判明
[2019/11/23 追記]
原因が判明しました。直接的な原因は、setting.pyの
SPLASH_URL = ‘http://localhost:8050’
を
SPLASH_URL= ‘http://172.21.0.2:8050’
に変更することで動きました。
参考までに、docker-compose.xmlと調査時のコマンドをのけておきます。
docker-compose.xml
version: '3'
services:
splash:
restart: always
image: scrapinghub/splash
container_name: mysplash
ports:
- "5023:5023"
- "8050:8050"
- "8051:8051"
docker-scrapy:
build: .
container_name: myscrapy
depends_on:
- splash
tty: true
mysplashのコンテナに入って、以下のコマンドを実行し、IPアドレスを確認する。
> docker exec -it mysplash /bin/sh $hostname -I 172.21.0.2
setting.pyを修正する。
# -*- coding: utf-8 -*-
SPIDER_MODULES = ['scraping.spiders']
NEWSPIDER_MODULE = 'scraping.spiders'
ROBOTSTXT_OBEY = False
#####add for Splash#######
# Connection was refused by other side: 111
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7'
DOWNLOAD_DELAY = 0.25
SPLASH_URL = 'http://172.21.0.2:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
One thought on “docker-compoesでpython(scrapy / splash)のスクレイピング環境構築”
Comments are closed.